开新的坑,我很期待的学习部分
本文使用的项目:
https://github.com/JoyChou93/java-sec-code
本文主要参考文章:
https://xz.aliyun.com/news/11118
https://drun1baby.top/2022/09/14/Java-OWASP-%E4%B8%AD%E7%9A%84-SQL-%E6%B3%A8%E5%85%A5%E4%BB%A3%E7%A0%81%E5%AE%A1%E8%AE%A1
JDBC场景的SQL注入 jdbc有两种方式执行sql语句,分别为PreparedStatement和Statement
Statement实现
1 2 3 4 5 String checkUserQuery = "select userid from xxx where userid = '" + username_reg + "'" ; Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery(checkUserQuery);
Statement会直接拼接sql语句,几乎所有的Statement拼接都会导致sql注入
所以有更安全的PreparedStatement,会对SQL语句进行预编译 ,一般实现
1 2 3 4 5 6 var statement = connection.prepareStatement("select password from sql_challenge_users where userid = ? and password = ?" ); statement.setString(1 , username_login); statement.setString(2 , password_login); var resultSet = statement.executeQuery();
Statement的SQL注入 现在看项目代码
这里就直接用了Statement拼接,当访问url http://localhost:8080/sqli/jdbc/vuln?username=1时,后端sql语句变成
select * from users where username = 1
这个username可控,直接用paylaod username=123' or '1'='1拼接就好了
Statement的SQL注入修复手段–预编译 项目代码后面 /jdbc/sec 接口写了修复方式,现在变成
1 2 3 4 String sql = "select * from users where username = ?" ;PreparedStatement st = con.prepareStatement(sql);st.setString(1 , username); ResultSet rs = st.executeQuery();
语句变成这样
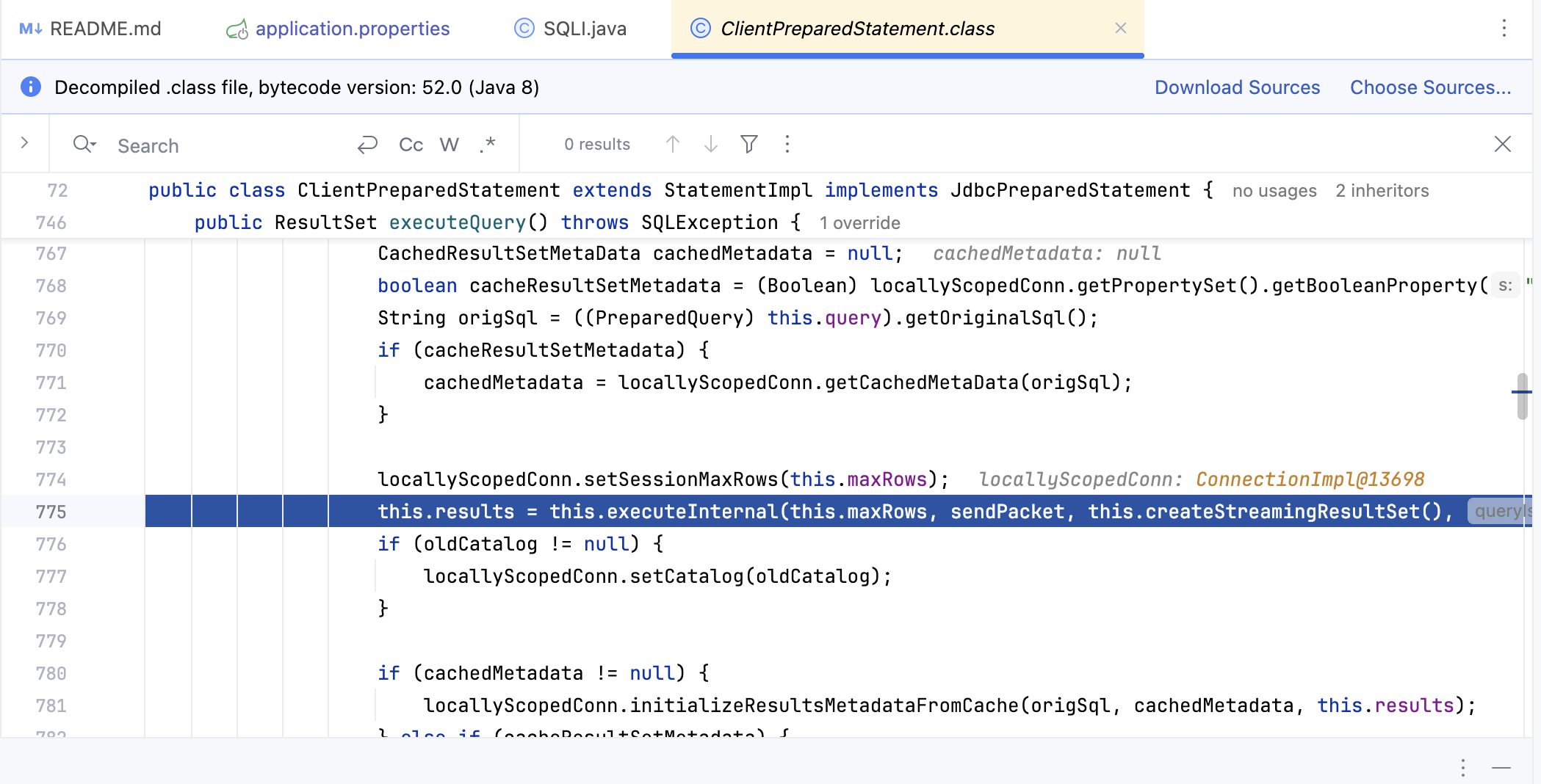
看一下究竟为什么这么写会修复sql注入,跟进executeQuery()方法看一下
在775行这个executeInternal()方法查看
一般 Internal 结尾的方法都是一些内部处理的方法
跟进去主要做了两件事,一是返回查询结果,二是返回查询时间(不截图了),然后这些结果包含在result里面,最后返回一个rs给程序
但是要明确的是 在预编译中,输入和SQL语句是完全分开的
这里我再找了别的文章 了解一下预编译究竟是怎么回事
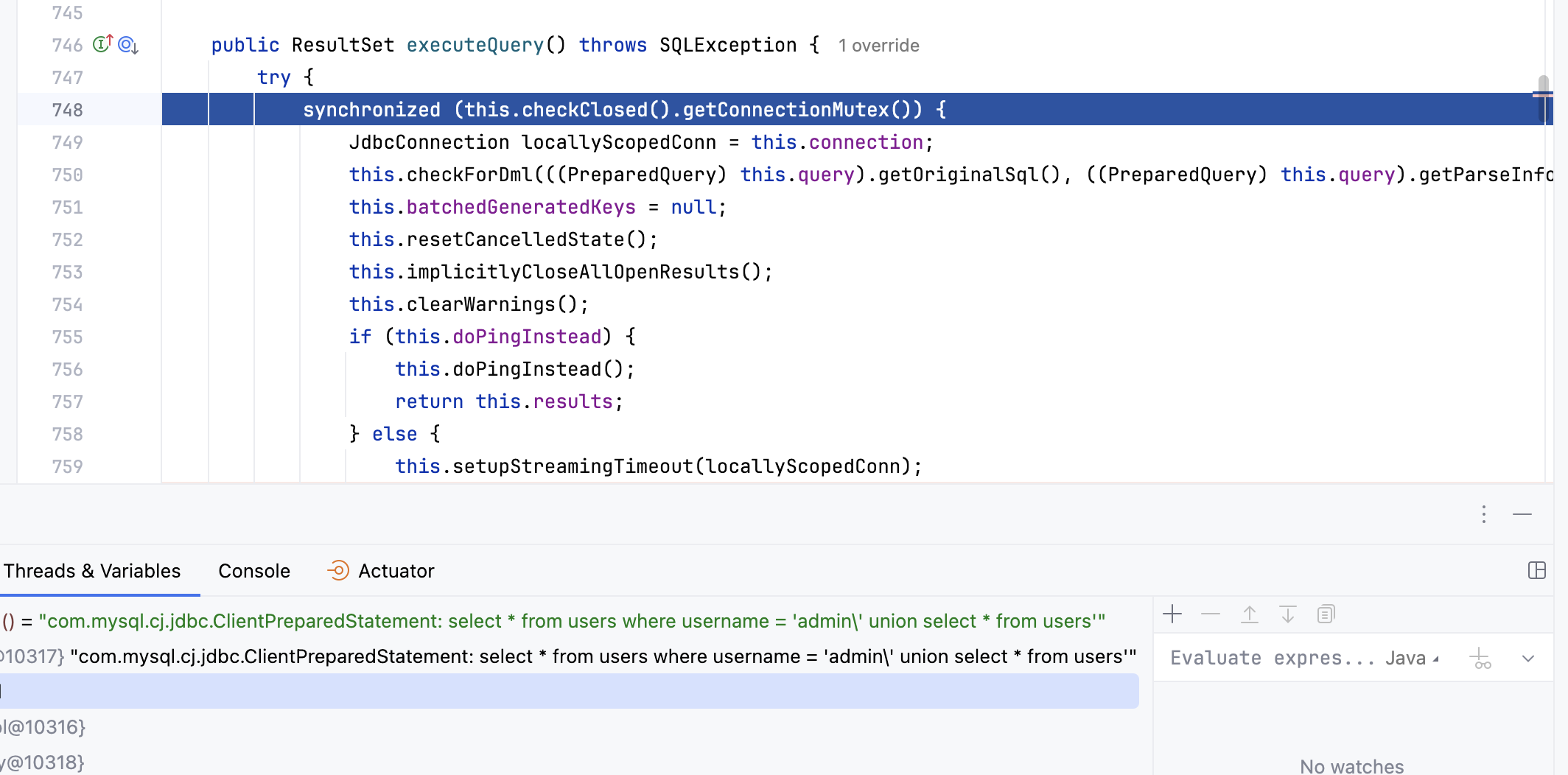
进到executeQuery()发现此时的语句后半部份有一个转义
1 'admin\' union select * from users'
可以看日志最后执行的sql语句就是
后面在这个方法里有一句
1 Message sendPacket = ((PreparedQuery<?>) this .query).fillSendPacket();
经过fillSendPacket()处理后查看sendPacket内容是字节数组,转成字符串看到的内容就是
1 select * from users where username = 'admin\' union select * from users'
所以说转义在 preparedStatement.setString 方法调用的时候完成,而 PreparedStatement 在发起请求前就把转义后的参数和 SQL 模板进行了格式化,最后发送到 MySQL 的时候就是一条普通的 SQL 。
可以说这是“假的预编译”,因为本质是对传入的数据转义而已
真的预编译 在jdbc连接路由地方加入参数useServerPrepStmts=true会开启真正的预编译
还是一样的payload
这里因为暂时找不到数据库日志,只能看到服务器日志,语句变成了
参考文章给的例子
1 2 Execute select * from s_user where username = '王五\' union select * from s_user' Prepare select * from s_user where username = ?
这个时候经过fillSendPacket()处理后查看sendPacket的内容是null
再到后面有一个 NativeSession.execSQL再进行具体实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public <T extends Resultset > T execSQL (Query callingQuery, String query, int maxRows, NativePacketPayload packet, boolean streamResults, ProtocolEntityFactory<T, NativePacketPayload> resultSetFactory, ColumnDefinition cachedMetadata, boolean isBatch) { try { return packet == null ? ((NativeProtocol) this .protocol).sendQueryString(callingQuery, query, this .characterEncoding.getValue(), maxRows, streamResults, cachedMetadata, resultSetFactory) : ((NativeProtocol) this .protocol).sendQueryPacket(callingQuery, packet, maxRows, streamResults, cachedMetadata, resultSetFactory); } }
这里有个小思考,“假的预编译”本质用的是转义,那是不是有可能绕过呢🤔。目前本人手法还太少常见方法还没办法绕过,先记着,说不定以后哪天就想到了
JDBC易产生的漏洞点 未使用占位符
PreparedStatement 只有在使用”?”作为占位符才能预防sql注入,直接拼接仍会存在sql注入漏洞
使用in语句 存在这样的场景
1 String sql = "delete from users where id in("+ delIds+ "); //存在sql注入
由于无法确定delIds含有对象个数而直接拼接sql语句提前闭合,造成sql注入
比如构造1) OR 1=1 -- ,变成
1 DELETE FROM users WHERE id IN (1 ) OR 1 = 1
解决方法是为遍历传入的 对象个数,使用“?”占位符
使用like语句 1 String sql = "select * from users where password like '%" + con + "%'"; / / 存在sql 注入
例如构造' OR '1'='1' --
1 SELECT * FROM users WHERE password LIKE '%' OR '1' = '1'
%和_
预编译是不能处理这个符号的, 所以需要手动过滤,否则会造成慢查询,造成 dos。
Order by、from 等关键字无法预编译 根据前面的内容,似乎只需要对要传参的位置使用占位符进行预编译时似乎就可以完全防止 SQL 注入,但是如果是order by,from这种就没办法预编译,原因有2点
JDBC的预编译占位符(?)会将传入的参数视为字符串值 ,自动添加单引号包裹。例如:
1 2 PreparedStatement pstmt = connection.prepareStatement("SELECT * FROM users ORDER BY ?" );pstmt.setString(1 , "username" );
此时,数据库会将'username'视为字符串常量而非字段名,导致排序逻辑错误或语法报错
语句结构化
简单理解就是前面那些能够预编译的语句是把查询语句结构固定住,我们只需要传入参数进去就可以,但是如果语句有order by,查询语句的结构会根据order by后面的字段改变,结构存在动态性,而预编译要求语句提前固定
Mybatis 下的 SQL 注入
SQL 语句一般是写在 Mapper 里面的,正常的应该是 Controller 层调 Service 层调 pojo 层,SQL 语句是写在 Mapper 文件里面的。所以如果是从代码审计的角度来看的话,我们可以直接来看 Mapper 层的代码。
mybatis的注入一一般是${Parameter}
看一下项目里的例子
1 2 3 4 5 6 7 8 9 @Select("select * from users where username = '${username}'") List<User> findByUserNameVuln01 (@Param("username") String username) ; @GetMapping("/mybatis/vuln01") public List<User> mybatisVuln01 (@RequestParam("username") String username) { return userMapper.findByUserNameVuln01(username); }
这里的尝试漏洞的原因是${username}是直接拼接的,这点喝之前的jdbc一样
payload admin' or '1'='1
Mybatis下的SQL注入防护 — 预编译 换成用 #{parameter}
项目里的修复方案
1 2 3 4 5 6 7 8 9 @Select("select * from users where username = #{username}") User findByUserName (@Param("username") String username) ; @GetMapping("/mybatis/sec01") public User mybatisSec01 (@RequestParam("username") String username) { return userMapper.findByUserName(username); }
这样就能防御
Mybatis易产生sql注入的情况 like关键字的模糊查询 用到like,使用#{}会报错,就有程序员把#改成%,这样就容易产生拼接问题
1 2 3 <select id ="findByUserNameVuln02" parameterType ="String" resultMap ="User" > select * from users where username like '%${_parameter}%' </select >
测试效果
正确写法
1 2 3 <select id ="findByUserNamesec" parameterType ="String" resultMap ="User" > select * from users where username like concat('%',#{_parameter}, '%') </select >
不同数据库的写法
1 2 3 4 5 6 mysql: select * from users where username like concat('%',#{username},'%') oracle: select * from users where username like '%'||#{username}||'%' sqlserver: select * from users where username like '%'+#{username}+'%'
还是要用#,为了不报错,还是要用到concat在前后拼接%
使用in语句 查询语句中有in直接使用#{}也是会报错,直接用%{}则会导致拼接
我们现在在mapper的xml配置文件多添加
1 2 3 <select id ="findByUserNameVuln04" parameterType ="String" resultMap ="User" > select * from users where id in (${_parameter}) </select >
1 2 3 4 5 @GetMapping("/mybatis/vuln04") public List<User> mybatisVuln04 (@RequestParam("id") String id) { return userMapper.findByUserNameVuln04(id); }
效果
正确修复 应该是使用foreach,而不是简单地把#换成%
定义一个新的接口
1 2 3 4 @GetMapping("/mybatis/sec04") public List<User> mybatisSec04 (@RequestParam("id") List id) { return userMapper.findByIdSec04(id); }
然后xml里面这么改
1 2 3 4 5 6 <select id ="findByIdSec04" parameterType ="String" resultMap ="User" > SELECT * from users WHERE id IN <foreach collection ="id" item ="id" open ="(" close =")" separator ="," > #{id} </foreach > </select >
现在就可以成功防护啦
原理就是foreach可以把查找的每一个要查询的字符分割,再配合#{}如果有特殊的字符也会转义
使用order by 和前面jdbc同理,和#{}一起使用会报错,解决方法还是要提前做好参数过滤
Mybatis-Plus 的 SQL 注入 这里换了个项目
https://github.com/Drun1baby/JavaSecurityLearning/tree/main/JavaSecurity/Java%20%E4%BB%A3%E7%A0%81%E5%AE%A1%E8%AE%A1/CodeReview/JavaSec-Code/MybatisPluSqli
部署完成
使用apply语句拼接sql 理想的apply漏洞场景 一种纯拼接的场景,很白给,实践中出现的概率非常小
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/mpVuln02") public List<Employee> mpVuln02 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.apply("id=" +id); return employeeMapper.selectList(wrapper); }
实际中直接使用selectList()就非常白给,几乎不可能这么写
如果真这么写了,那注入效果
实际的apply使用场景 1 2 3 4 5 6 7 @RequestMapping("/mybatis_plus/mpVuln01") public Employee mpVuln01 (String name, String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.eq("name" ,name).apply("id=" +id); Employee employee = employeeMapper.selectOne(wrapper); return employee; }
apply()算一个多参请求,要有id和name配合来确定数据
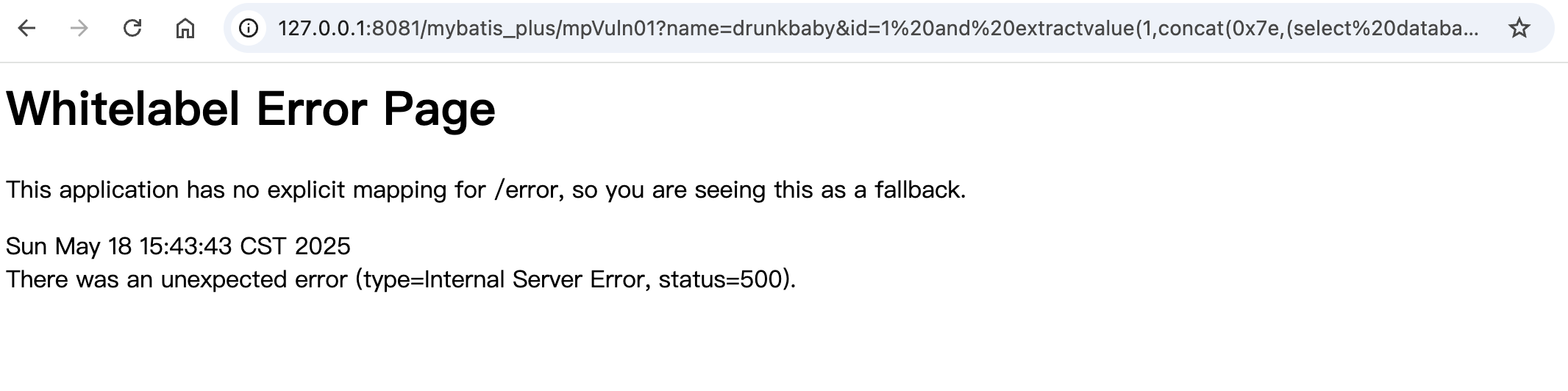
假设现在payload这么写
1 ?name=drunkbaby&id=1%20and%20extractvalue(1,concat(0x7e,(select%20database()),0x7e))
只有报错注入才可能成功,前面那些or 1=1 的拼接没办法实现
1 Employee employee = employeeMapper.selectOne(wrapper);
这里使用了selectOne(),只有一行数据出来
虽然客户端只看到报错,但是看服务端数据
这里成功打印出数据库,报错注入是可行的,在实际场景中如果遇到会打印报错信息的业务,我们就有机会sql注入
apply场景的防护 还是用预编译
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/mpSec02") public List<Employee> mpSec02 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.apply("id={0}" ,id); return employeeMapper.selectList(wrapper); }
很简单,要 apply 的地方加上 {0} 即可
后端现在看到这样的数据
last方法产生的sql注入 last()方法经过重写,有两个实现方法
1 2 last(String lastSql) last(boolean condition, String lastSql)
在lastsql我们可以直接写sql语句,新写一个接口
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/last") public List<Employee> mpVuln03 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.last("order by " + id); return employeeMapper.selectList(wrapper); }
这样也是会尝试拼接问题,它无视优化规则,直接拼接到语句最后
exists/notExists 拼接产生的SQL 注入 1 2 3 4 5 exists(String existsSql) exists(boolean condition, String existsSql) notExists(String notExistsSql) notExists(boolean condition, String notExistsSql)
exists运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False
也是直接拼接
两个接口分别这么写
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/mpVuln04") public List<Employee> mpVuln04 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.exists("select * from employees where id = " + id); return employeeMapper.selectList(wrapper); }
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/mpVuln05") public List<Employee> mpVuln05 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.notExists("select * from employees where id = " + id); return employeeMapper.selectList(wrapper); }
having语句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
在mybatis_plus中
1 2 having(String sqlHaving, Object... params) having(boolean condition, String sqlHaving, Object... params)
接口
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/mpVuln06") public List<Employee> mpVuln06 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().groupBy("id" ).having("id >" + id); return employeeMapper.selectList(wrapper); }
Order by语句 orderBy
1 orderBy(boolean condition, boolean isAsc, R... columns)
orderByAsc
1 2 orderByAsc(R... columns) orderByAsc(boolean condition, R... columns)
orderByDesc
1 orderByDesc(R... columns)
接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public List<Employee> orderby01 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().orderBy(true , true , id); return employeeMapper.selectList(wrapper); } @RequestMapping("/mybatis_plus/orderby02") public List<Employee> orderby02 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().orderByAsc(id); return employeeMapper.selectList(wrapper); } @RequestMapping("/mybatis_plus/orderby03") public List<Employee> orderby03 ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().orderByDesc(id); return employeeMapper.selectList(wrapper); }
group by 1 2 groupBy(R... columns) groupBy(boolean condition, R... columns)
和order by原理一样
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/groupBy") public List<Employee> groupBy ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().groupBy(id); return employeeMapper.selectList(wrapper); }
inSql/notinSql 1 2 3 4 5 inSql(R column, String inValue) inSql(boolean condition, R column, String inValue) notInSql(R column, String inValue) notInSql(boolean condition, R column, String inValue)
接口
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/insql") public List<Employee> inSql ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().inSql(id, "select * from employees where id >" + id); return employeeMapper.selectList(wrapper); }
1 2 3 4 5 6 @RequestMapping("/mybatis_plus/notinSql") public List<Employee> notinSql ( String id) { QueryWrapper<Employee> wrapper = new QueryWrapper <>(); wrapper.select().notInSql(id, "select * from employees where id >" + id); return employeeMapper.selectList(wrapper); }
Wrapper自定义sql 和前面一样 不赘述
分页插件到SQL注入 一个分页插件是自带的addOrder(),还有一个是order by
先配置分页插件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.drunkbaby.config; import com.baomidou.mybatisplus.annotation.DbType; import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor; import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class MybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor () { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor (); PaginationInnerInterceptor pageInterceptor = new PaginationInnerInterceptor (); pageInterceptor.setOverflow(false ); pageInterceptor.setMaxLimit(500L ); pageInterceptor.setDbType(DbType.MYSQL); interceptor.addInnerInterceptor(pageInterceptor); return interceptor; } }
addOrder()
在 MyBatis-Plus 的分页插件中,addOrder 方法用于 动态添加排序规则 ,允许开发者为分页查询指定排序字段及顺序
接口
1 2 3 4 5 6 7 8 9 @RequestMapping("/mybatis_plus/PageVul01") public List<Person> mybatisPlusPageVuln01 (Long page, Long size, String id) { QueryWrapper<Person> queryWrapper = new QueryWrapper <>(); Page<Person> personPage = new Page <>(1 ,2 ); personPage.addOrder(OrderItem.asc(id)); IPage<Person> iPage= personMapper.selectPage(personPage, queryWrapper); List<Person> people = iPage.getRecords(); return people; }
1 Page<Person> personPage = new Page<>(1,2); // 里面的参数可以自定义
payload也是比较有要求
1 2 3 4 ?id=1%20and%20extractvalue(1,concat(0x7e,(select%20database()),0x7e))) // 或者是 ?id=1' and sleep(5)
必须是通过盲注的形式,如果是普通的注入,是不会有回显的;因为这里分页查找,size 就把你的数据数量限定死了,如果超过这个数据就会报错,所以只能盲注。
pagehelper 原理和order by一样
因为Order by排序时不能进行预编译处理,所以在使用插件时需要额外注意如下function,同样会存在SQL注入风险:
com.github.pagehelper.Page
主要是setOrderBy(java.lang.String)方法
com.github.pagehelper.page.PageMethod
主要是startPage(int,int,java.lang.String)方法
com.github.pagehelper.PageHelper
主要是startPage(int,int,java.lang.String)方法
Mybatis plus sql注入的修复 写好过滤
Hibernate 框架下的 SQL 注入
Hibernate 是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得 Java 程序员可以随心所欲的使用对象编程思维来操纵数据库。
Hibernate 可以使用 hql 来执行 SQL 语句,也可以直接执行 SQL 语句,无论是哪种方式都有可能导致 SQL 注入
HQL 比较好理解,存在这样的语句有sql注入问题
1 String hql = "from People where username = '" + username + "' and password = '" + password + "'";
如果要避免,有下面几种方法
命名参数 1 2 3 4 Query<User> query = session.createQuery("from users name = ?1" , User.class); String parameter = "g1ts" ;Query<User> query = session.createQuery("from users name = :name" , User.class); query.setParameter("name" , parameter);
位置参数 1 2 3 String parameter = "g1ts" ;Query<User> query = session.createQuery("from users name = ?1" , User.class); query.setParameter(1 , parameter);
命名参数列表 1 2 3 List<String> names = Arrays.asList("g1ts" , "g2ts" ); Query<User> query = session.createQuery("from users where name in (:names)" , User.class); query.setParameter("names" , names);
类实例 1 2 3 user1.setName("g1ts" ); Query<User> query = session.createQuery("from users where name =:name" , User.class); query.setProperties(user1);
HQL拼接
这种方式是最常用,而且容易忽视且容易被注入的,通常做法就是对参数的特殊字符进行过滤,推荐大家使用 Spring工具包的StringEscapeUtils.escapeSql()方法对参数进行过滤:
1 2 3 4 5 import org.apache.commons.lang.StringEscapeUtils;public static void main (String[] args) { String str = StringEscapeUtils.escapeSql("'" ); System.out.println(str); }
SQL
Hibernate支持使用原生SQL语句执行,所以其风险和JDBC是一致的,直接使用拼接的方法时会导致SQL注入
1 Query<People> query = session.createNativeQuery("select * from user where username = '" + username + "' and password = '" + password + "'" );
正确写法
1 2 3 String parameter = "g1ts" ;Query<User> query = session.createNativeQuery("select * from user where name = :name" ); query.setParameter("name" ,parameter);
总结 写完这个笔记算是接触了三个主要数据库连接方法对应会尝试sql注入的点,主要就是给用户自由拼接的空子,防御靠预编译和参数过滤,印象比较深的是这个order by为什么不能预编译的问题。除此之外细节看这些东西是比较细的,如果以后真的自己审计,记住几个重点查看的地方,和项目漏洞寻找思路。