
前言
最近开始接触java安全,最离不开的就是反序列化利用和那些出名的CC链。前两天学了Java序列化和反序列化,还有反射啊这些概念,其实基础还不是很扎实,还要学习。说回来,接触反序列化第一条链子就是URLDNS,对大佬来说还是很好理解的,但是我这两天看了很多博客和视频,实践下来发现里面也是有很多注意点,于是写了笔记记录下来,描述的过程帮助我把原理都顺下来,才算是消化下去了。
链子分析
这个链子来源是这个知名工具,看下里面标出来的构造链

我们直接看实现代码
1 | package com.example; |
这几行三下五除二理想状态下就能在反序列化的过程中实现DNS解析,为什么呢?!
这里我们跟进一下hashmap的put方法
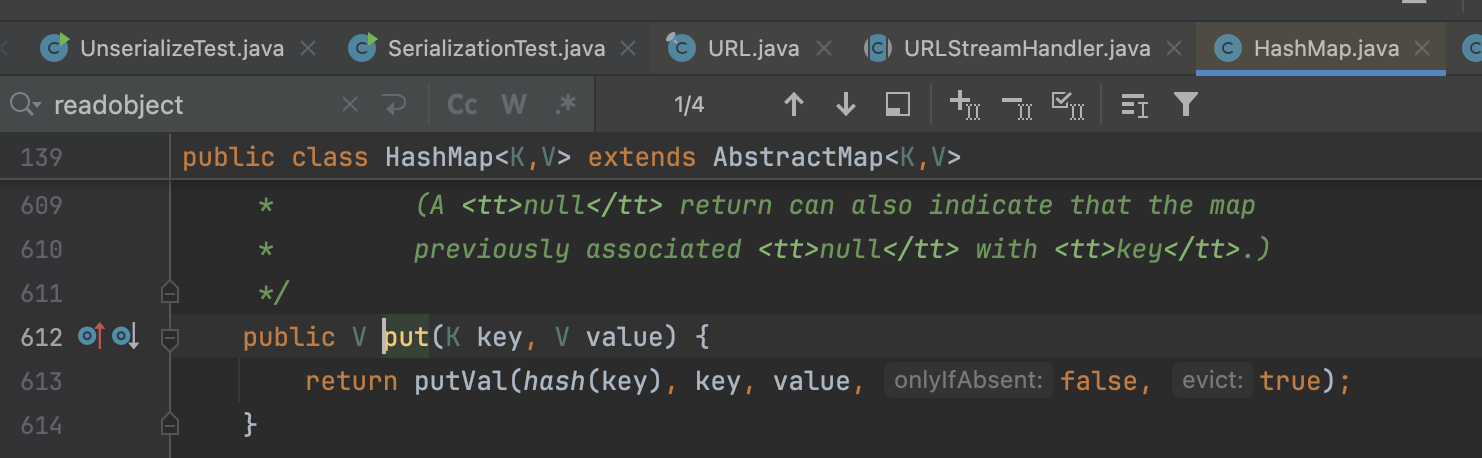
来到HashMap的put方法,我们会发现我们传入了key和value,里面会调用hash()方法,再跟进
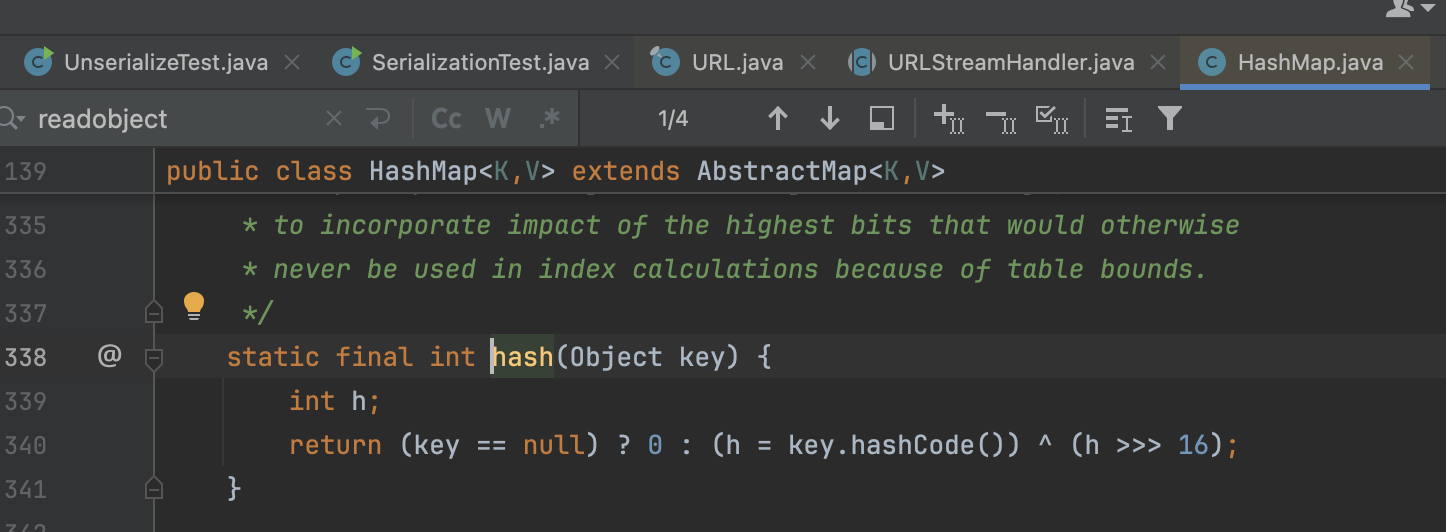
里面使用了hashCode,这是一个很常见的函数,原生Object类里面就有,也有很多类会重写
然后我们看到URL里面,里面就有hashCode

URL里面的hashCode调用了handler.hashCode,我们再跟进

来到了URLStreamHandler,里面的hashCode调用了getHostAddress函数,这个函数会触发DNS解析,就达到了我们最后的目的。
一开始学的时候冥冥之中我知道最后hashmap的put会触发URL的hashCode,但是为什么会触发呢(其实这里就是我基础薄弱的体现)
后来和GPT聊了一下,和大哥聊了一下,重点在这里
看这里hash函数里面调用的hashCode是取决于key的,也就是说,如果我们传入的这个key属于的那个类里面有自己重写的hashCode,程序就会调用新写的hashCode,而不是原来的。
应用到URL的例子,我们hashmap调用put->hash,里面调用的hashCode是key也就是URL类的hashCode。一切都清晰了起来!
1 | HashMap.put() |
所以这就是链子的过程,吃透了之后就觉得不复杂了。但是我们之间执行上面的代码却发现dns解析的次数效果不符合我们的预期,这就引入到我们的下一步分析
利用反射复现出理想效果
我们在序列化操作的时候就会收到DNS解析,这不是我们理想中的效果。
从原理看,URL的hashCode有一个判断
1 | public synchronized int hashCode() { |
会判断hashCode的值,如果不是-1会直接返回hashCode的值,而不会进入我们想要调用的handler.hashCode
在序列化的时候会触发是因为URL里面初始化定义hashCode是-1,所以一开始会调用一次,而且后面赋值更改了之后就进不去了。
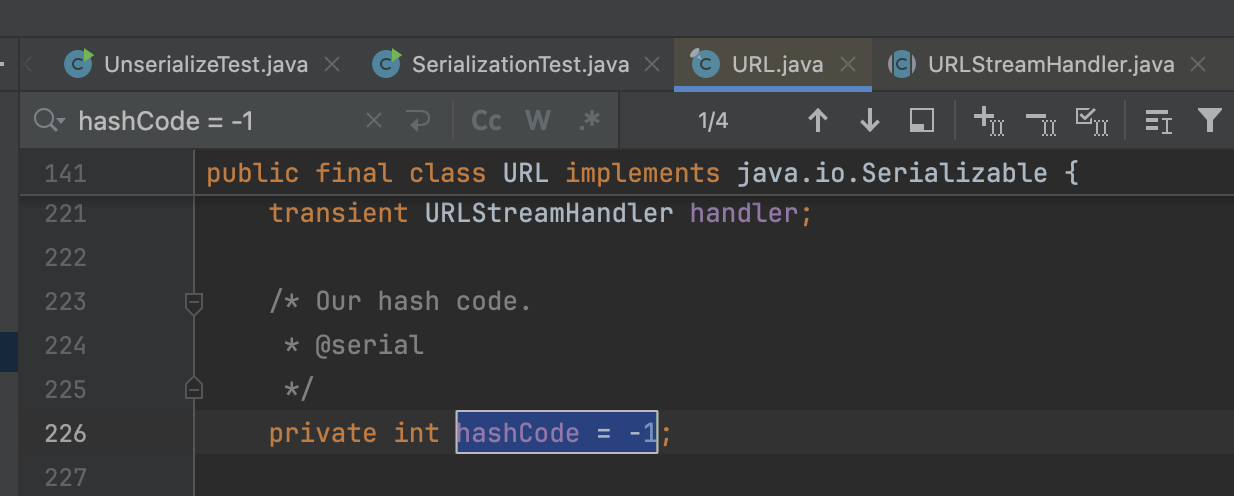
所以按之前什么的代码执行,序列化的时候就出现了dns解析,后面反序列化的时候却没发生,这明显不是我们理想中的效果。
那我们现在要做的是保证整个实验过程,只有序列化和反序列化才会触发handler.hashCode,那么我们就要解决两个问题:第一是put之前hashmap的hashCode不是-1,put之后再把它变回-1。这里我们就用到反射
Java 反射机制允许在运行时动态地获取类的信息(如字段、方法、构造函数等),并操作类的对象,从而实现更加灵活和通用的代码。
反射的流程是先获取类,然后实例化对象,获取类里面的属性,做一些修改对象属性或者调用方法等操作。
看实现代码
1 | URL u = new URL("http://diru.callback.red"); |
利用反射进行一系列操作,最后保证只有在反序列化的时候才能看到DNS解析,至此,链子就分析完成了。
最后
感谢前面各位师傅写的解释教学,这里就不一一列出来了。本人还在学习,基础不是非常扎实,如果这篇文章哪里写的不好,非常欢迎找我指正交流,感谢🙏